

Polylang | Miden | Risc Zero | Noir (Barretenberg) | Leo | |
|---|---|---|---|---|---|
Frontend (Language) | Typescript-like | MASM (Assembly) | Rust, C, C++ | Rust-like | Leo (DSL) |
ZK | STARK | STARK / zkVM | STARK / zkVM | SNARK | SNARK |
Unbounded Programs | ✅ | ✅ | ✅ | ❌ | ❌ |
Audit | ❌ Planned 2024 | ❌ Planned 2024 | ❌ Planned 2024 | ❌ Planned 2024 | ❌ Planned 2023 |
External Libraries | ❌ | ⚠️ | ✅ | ⚠️ | ⚠️ |
EVM Verifier | ⚠️ | ⚠️ | ✅ | ✅ | ❌ |
GPU | ✅ Metal | ✅ Metal | ✅ Metal, CUDA | ❌ | ❌ |
Assert | 0.05s | 0.03s | 6.10s | 0.01s | 3.08s |
Optimised Hashes | RPO +2 more | RPO +2 more | SHA-256 | Pedersen +3 more | Pedersen +4 more |
SHA-256 Hash | |||||
1k bytes | 21.24s | 19.91s | 6.14s | 3.33s | |
10k bytes | 225.84s | 176.14s | 6.18s | 32.25s | |
Pedersen Hash | |||||
1k bytes | ❌ | ❌ | ❌ | ❌ | 1.95s |
10k bytes | ❌ | ❌ | ❌ | ❌ | 2.24s |
RPO Hash | |||||
1k bytes | 0.16s | 0.03s | ❌ | ❌ | ❌ |
10k bytes | 1.78s | 0.29s | ❌ | ❌ | ❌ |
Fibonacci | |||||
1 | 0.03s | 0.03s | 6.14s | 0.01s | 1.91s |
10 | 0.05s | 0.03s | 6.10s | 0.01s | 1.89s |
100 | 0.16s | 0.03s | 6.12s | 0.01s | 1.88s |
1,000 | 2.50s | 0.08s | 6.12s | 0.01s | 1.89s |
10,000 | 21.22s | 0.57s | 6.13s | 0.01s | 1.88s |
100,000 | 219.98s | 9.44s | 6.13s | 0.01s | 🚧 |
Merkle Tree | |||||
Membership Proof | |||||
2^10 | 🚧 | 0.06s | 6.17s | 3.46s | 🚧 |
Merge | |||||
1 + 1 | 🚧 | 0.06s | 6.16s | 🚧 | 🚧 |
Last Updated:
We provide important caveats in the info and buttons
Follow us on Twitter X
To get updates on zk-bench follow the Polybase Labs team.
FAQ
Who made this and why?
Hi, I'm Calum, CTO of Polybase Labs 👋
We made ZK-bench to help the ZK community better understand the trade-offs and performance of different frameworks. It can be really hard to setup and run your own benchmarks for each of the growing numbers of frameworks. Whilst the frameworks themselves often provide a set of benchmarks, it can be hard to make direct comparisons as there are many factors that can affect the performance of a benchmark. We've tried hard to create similar conditions for the benchmarks across all frameworks (keeping in mind that these frameworks have different levels of abstraction, see below). We aim to provide a practical comparison between benchmarks, so that protocol developers can answer the question - which framework should I use?
We're also the team behind Polylang, and we wanted to be able to understand the performance we're able to achieve in comparison to other frameworks.
Which is the best framework?
There is no “best” framework. As you can see from the table above, there are a lot of caveats and trade offs. You should choose the framework that best meets your needs, which will depend on what kind of application you are building. In addition to what we have provided above, you should check the developer experience for each framework, and that the level of abstraction meets your needs. If you have questions about which framework is best for you, feel free to reach out on Twitter X @polybase_xyz or to me directly @calummoore.
Are these frameworks even comparable?
Are we comparing 🍎 to 🍏? It depends.
These frameworks are all different levels of abstraction, but at the end of the day they all trying to achieve the same thing - prove some computation in zero knowledge.
There are generally three levels of abstraction:
- High level language (HLL/DSL) - Rust, C, Noir, Polylang
- Intermediate representation (IR) - VAMP-IR, ACIR, Miden-IR
- Circuit, Assembly, Byte Code - Miden Assembly, Risc-V,
A developer should choose the level of abstraction they want, keeping in mind that each level of abstraction generally reduces performance, but increases developer speed, maintainability and auditability. We directly compare different levels of abstraction because this is a valid choice that developers face when choosing a framework to use.
Our goal is to provide a living, breathing document of where ZK frameworks are today (not what they could be). We want this to be a practical (not theoretical) resource for protocol developers who are faced with the decision, what ZK stack should I use? If you're looking to perform zk research or understand performance at a constraint level then we highly recommend watching this talk at ZK Summit 10.
We also wanted our framework benchmarks to be holistic, while developing in ZK we've often found that defined/expected performance doesn't always match reality - so we wanted to provide something that tests a framework end to end.
Noir can compile to many backends?
That is definitely the goal for Noir, but right now it compiles only to one: Barretenberg. When more backends are added to Noir, we will add them as separate benchmarks. We also plan to benchmark using Barretenberg directly, as this is a valid choice for developers, albeit with a higher development cost.
X could be optimised further?
It probably can. In this case, it's probably one of two things:
-
We did not write a fair benchmark - raise a PR
-
The framework hasn't optimised for X yet, but it could theoretically be faster - I'm sure it could (everything can), but we're benchmarking things that exist today, because that's what a developer has available to them when they use a framework
What is ZK?
ZK (zero knowledge) is a type of cryptography that allows a proof (a kind of certificate) to be generated that allows one party to prove to another that they know a value (or that some condition holds true), without revealing any information about the value itself.
There are two main components to ZK:
- Zero Knowledge - the ability to run computation without revealing all of the inputs, but having the output be trusted
- Provable computation - proves the code ran as designed, and therefore the output can be trusted
Here's a simple example to demonstrate the idea of provable computation. Below the code checks if the input provided is over 18. If we ran this in zero knowledge, we could generate a proof that the input value was > 18 without revealing the actual number:
function isOver18(age: number): boolean {
return age > 18;
}
What’s the difference between a STARK and a SNARK?
These are two different approaches to provable zero knowledge computation.
You should prefix everything below with "in general" - there are always exceptions to the rule!
| Feature | SNARK | STARK |
|---|---|---|
| Definition | Succinct Non-interactive ARguments of Knowledge | Scalable Transparent ARguments of Knowledge |
| Setup Phase | Typically requires a trusted setup to generate a shared secret key. Parameters must be kept secret | Does not require a trusted setup |
| Turing Completeness | Program must be bounded at compile time | Fully Turing complete |
| Transparency | Less transparent due to the trusted setup | More transparent due to the lack of a trusted setup |
| Proof Size | Generally produces shorter proofs | Generates longer proofs, proof size is still non-linear |
| Verification Time | Usually offers faster verification times | Slower verification, especially with larger data. Not suitable for Ethereum |
| Prover Time | Generally efficient but depends on the specific construction | Proving time can be longer, particularly for larger datasets |
| Cryptographic Assumptions | Relies on stronger, more specific assumptions | Relies on lesser cryptographic assumptions, more "future-proof" |
| Quantum Resistance | Generally not quantum-resistant | Generally quantum-resistant |
What are unbounded programs?
These are programs which have inputs or logic where the number of cycles or iterations is not known at compile time. For example, a program that iterates over a list of items and checks if each item is greater than 18. The number of items in the list is not known at compile time, so the program is unbounded.
In general, SNARKs require a program to be bounded at compile time, whereas STARKs do not.
Unbounded Program
The following is an example of a program that is unbounded, as you can see the number of items in the list is not known at compile time as it is supplied as an argument when calling the program.
function sum(list: number[]): number {
let total = 0;
for (let i = 0; i < list.length; i++) {
total += list[i];
}
return total;
}
Bounded Program
For frameworks that require a bounded program, you would have to explicitly define the number of items in the list, for example:
function sum(list: number[10]): number {
let total = 0;
for (let i = 0; i < list.length; i++) {
total += list[i];
}
return total;
}
Bounded Programs with Recursive Proofs
It's possible to use ZK recursive proofs to break up a bounded program, to allow it to be effectively unbounded. This could be done either at the application level or the framework level.
At the application level, the developer would break up their program at logical points. For example, imagine we're building a zk-chain, and we want to prove an unbounded number of transactions per block (i.e. some blocks have 10 txns, others 20, etc). Instead of proving all of the transactions in a single proof, we could generate each proof, merging it with the last proof until we've included all txns. In the end we'd have one proof, that could contain any number of txns.
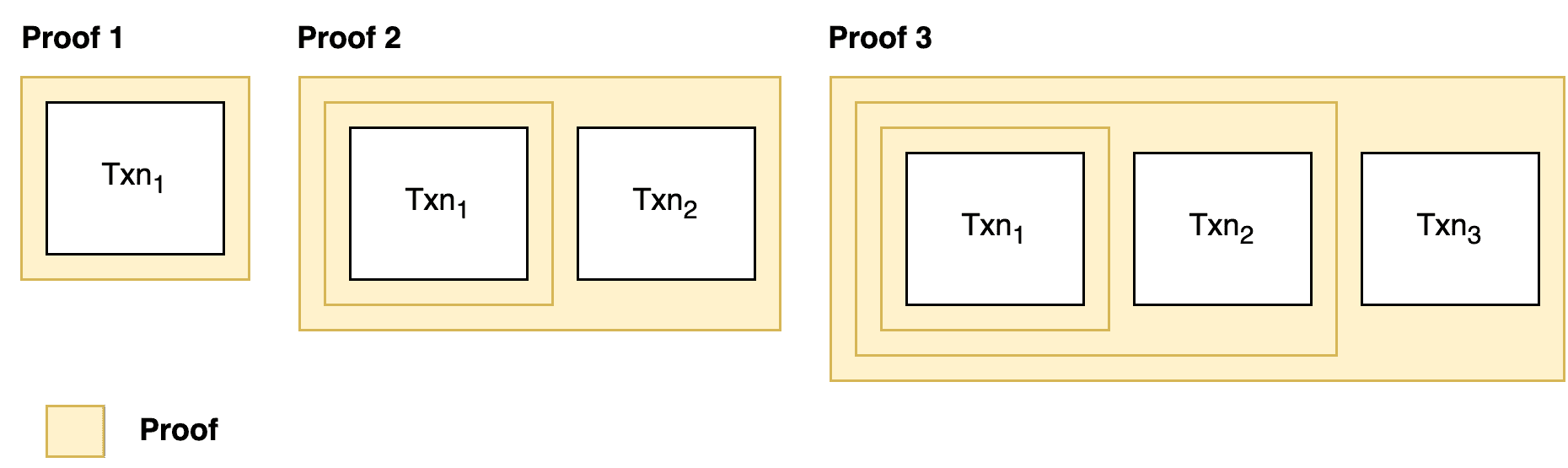
At the framework level, the frontend language or IR (intermediate representation) could translate for loops and unbounded inputs into separate program proofs, and then merge them for the user. This would be easier for the user, although we're not aware of any framework that provides this functionality today.
What is a ZK Recursive Proof?
A ZK recursive proof (often just called "recursion") is the ability to verify a proof, or many proofs, into another proof. There's nothing crazy going on here. Verification of proofs is simply a computation and ZK already enables proving of arbitrary computations.
Recursion has a lot of benefits, it allows us to:
- Turn bounded programs into practically unbounded programs
- Break up larger computations into multiple parts, useful for:
- RAM constrained environments like the browser
- Parallazing proofs across many different machines
- Aggregating multiple proofs into a single proof (e.g. to minimize network bandwidth)
How do you run the benchmarks?
We run the benchmarks using a Github Action using a self-hosted runner,
running on a dedicated shared AWS instance (still fighting with AWS to give us access to a dedicated instance).
Benchmarks are updated automatically whenever we update the benchmarks or the versions of the frameworks we are testing.
What benchmark tool do you use?
We actually created our own 😅, which you can find here on crates.io. We tried using criterion which is pretty much the default for Rust, but it didn't really serve our needs for the kinds of tests we are running. Criterion is tailored for nanosecond-level performance measurements of quick, simple functions, but we needed something that worked well with longer running benchmarks (ZK is still quite slow in many cases). We were also able to automatically profile the memory requirements of each benchmark, which is something we couldn't do with criterion.
How much does it cost to run the benchmarks?
Actually quite a lot 😅, we burned through $600 in a week of AWS + Github Actions. We hope to add some bigger machines soon too 😬.
What’s next on the roadmap?
These benchmarks should be a living breathing thing, we’re committed to improving it over time, and we hope you join in by raising a PR of your own.
We have a couple of ideas of things we’d like to tackle next -
- Browser benchmarks
- More common/real world programs
- Recursive proof benchmarks
- Loading large amounts of data into ZK frameworks
We’d like this to be community driven, let us know on Twitter what you’d like us to work on, or better yet - raise a PR!
Can you benchmark X or add framework Y?
Sure, just submit a PR 😉